Getting Started with Apache Kafka and Spring
 Apache Kafka is a powerhouse in the world of distributed systems, acting as a message broker that bridges services with efficiency and resilience. Whether you’re building microservices, streaming data pipelines, or log aggregation systems, Kafka—especially when paired with Spring—offers a robust solution. In this blog post, we’ll explore Kafka’s core concepts, its problem-solving prowess, real-world use cases, and how Spring makes it a breeze to integrate. Let’s dive in!
Apache Kafka is a powerhouse in the world of distributed systems, acting as a message broker that bridges services with efficiency and resilience. Whether you’re building microservices, streaming data pipelines, or log aggregation systems, Kafka—especially when paired with Spring—offers a robust solution. In this blog post, we’ll explore Kafka’s core concepts, its problem-solving prowess, real-world use cases, and how Spring makes it a breeze to integrate. Let’s dive in!
Why Kafka?
The Problem: Tight Coupling
In traditional architectures, services often depend directly on one another. If Service A needs data from Service B, it calls B and waits for a response. But what happens if B is slow or down? Service A slows down or fails too, creating a ripple effect that disrupts your entire business.
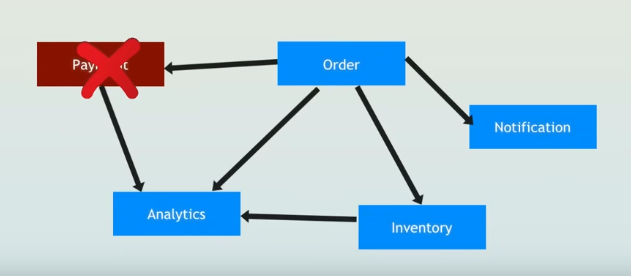 Diagram showing the Order service directly calling Payment (marked with an X to indicate failure), Analytics, Inventory, and Notification services, illustrating tight coupling.
Diagram showing the Order service directly calling Payment (marked with an X to indicate failure), Analytics, Inventory, and Notification services, illustrating tight coupling.
The Kafka Solution: Decoupling with a Queue
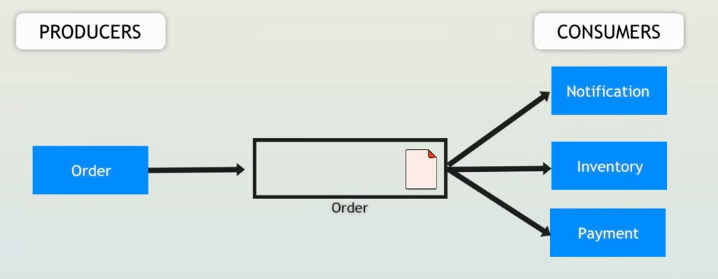
Kafka introduces a message broker to decouple these services, using topics to facilitate asynchronous communication. Instead of direct calls, the Order service publishes events to Kafka topics, and downstream services consume these events at their own pace. Here’s how Kafka transforms the scenario:
Order Service: Publishes an event to a topic like order-placed (e.g., “Order #123 placed”).
Kafka Topics:
order-placed: Subscribed to by Payment, Analytics, Inventory, and Notification.
Downstream Services:
Paymentconsumes the event and processes the payment when it’s back online.Analyticslogs the order for reporting.Inventoryupdates stock levels.Notificationsends a confirmation email.
The Benefits:
- Asynchronous Processing: The Order service doesn’t wait—it publishes the event and moves on to the next order.
- Fault Tolerance: If Payment is down, the event stays in the order-placed topic until Payment recovers. Other services (like Analytics) can still process the event immediately.
- Scalability: Each service can scale independently. For example, Inventory can add more consumers to handle peak loads without affecting Order.
With Kafka, the Order service is no longer at the mercy of its dependencies. The system becomes resilient, scalable, and responsive, even under failure conditions.
Kafka Core Concepts
To wield Kafka effectively, you need to grasp its building blocks. Here’s a rundown:
- Event/Message: The data unit Kafka handles—like a “payment request” or “log entry.”
- Topic: A named queue for categorizing events (e.g., payment-requests). Think of it as a channel.
- Producer: An application sending messages to a topic (e.g., the Order service).
- Consumer: An application subscribing to a topic to process messages (e.g., the Payment service).
- Consumer Group: A set of consumers sharing the load of a topic. Kafka distributes partitions among group members dynamically for scalability.
- Partition: A topic can be split into partitions for parallelism. Each partition has its own producers and consumers, stored on a Kafka broker.
- Kafka Broker: A server instance managing topics, partitions, and message delivery.
- Replica: Copies of a partition across brokers for redundancy and fault tolerance.
- Dead Letter Topic (DLT): A special topic for messages that fail processing after retries, preserving them for debugging or recovery.
Spring Kafka simplifies these concepts with annotations like @KafkaListener for consumers and KafkaTemplate for producers, as we’ll see later.
Kafka’s Evolution: ZooKeeper vs. KRaft
Kafka’s architecture has evolved, particularly in how it manages its brokers.
ZooKeeper (Legacy)
 Historically, Kafka relied on ZooKeeper, an external coordination service, to:
Historically, Kafka relied on ZooKeeper, an external coordination service, to:
- Track broker metadata (e.g., which brokers are alive).
- Assign partition leaders.
- Store configurations (e.g., replication factor, partition count).
ZooKeeper runs separately (port 2181), syncing with Kafka, which adds complexity and startup latency.
KRaft (Kafka Raft)
Introduced in Kafka 2.8 and production-ready by 3.3, KRaft replaces ZooKeeper with a built-in Raft consensus protocol:
- Some Kafka brokers double as controllers, forming a quorum to manage metadata.
- Metadata is stored in a Kafka topic (__cluster_metadata), leveraging Kafka’s log-based storage.
KRaft vs. ZooKeeper
| Aspect | KRaft | ZooKeeper |
|---|---|---|
| Integration | Built into Kafka | External service |
| Startup Time | Faster (single system) | Slower (ZooKeeper + Kafka sync) |
| Scalability | Millions of partitions | ~10,000 partitions (ZooKeeper limit) |
| Complexity | Lower (one system to manage) | Higher (two systems) |
Why KRaft? It simplifies operations, scales better, and aligns with Kafka’s log-centric design. Spring Kafka supports both, but KRaft is the future (ZooKeeper is deprecated in Kafka 3.7).
Kafka Use Cases
Kafka shines in diverse scenarios, especially with Spring’s integration:
- Message Queuing: Decouple services (e.g., Order and Payment) for resilience.
- Streaming Data: Feed real-time data to Spark Streaming or Flink via Kafka topics.
- Log Aggregation: Collect logs from services and send them to tools like ELK (Elasticsearch, Logstash, Kibana).
- Data Replication: Sync data across systems or regions.
- Monitoring & Alerting: Stream metrics to monitoring tools and trigger alerts.
Spring enhances these with @KafkaListener for consumers and KafkaStreams for processing, as we’ll explore.
Kafka in Action with Spring: A Practical Example
 Let’s see Kafka in a Spring Boot app, combining a producer, consumer, REST API, and test.
Let’s see Kafka in a Spring Boot app, combining a producer, consumer, REST API, and test.
Setup: Kafka on Docker
Use the bitnami/kafka image for simplicity:
docker run -d --name kafka -p 9092:9092 \
-e KAFKA_ENABLE_KRAFT=yes \
-e KAFKA_CFG_PROCESS_ROLES=broker,controller \
-e KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \
-e KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@localhost:9093 \
-e KAFKA_KRAFT_CLUSTER_ID=123 \
-e KAFKA_CFG_NODE_ID=1 \
bitnami/kafka:latest
This runs a single-node Kafka with KRaft.
Producer Class
@Service
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String message) {
kafkaTemplate.send("messages", message);
}
}
Consumer Class with DLT
java
@Component
public class KafkaConsumer {
private static final Logger LOG = LoggerFactory.getLogger(KafkaConsumer.class);
@RetryableTopic(attempts = "3", backoff = @Backoff(delay = 2000)) //Retries failed messages 3 times, then sends to messages-dlt.
@KafkaListener(topics = "messages", groupId = "my-group")
public void listen(String message) {
LOG.info("Received: {}", message);
if (message.contains("fail")) {
throw new RuntimeException("Processing failed");
}
}
@DltHandler //Logs failures
public void handleDlt(String message) {
LOG.info("DLT Received: {}", message);
}
}
REST API Controller
@RestController
@RequestMapping("/api")
public class MessageController {
@Autowired
private KafkaProducer producer;
@PostMapping("/send")
public ResponseEntity<String> sendMessage(@RequestBody String message) {
producer.sendMessage(message);
return ResponseEntity.ok("Message sent: " + message);
}
}
Hit /api/send with curl:
curl -X POST -H "Content-Type: text/plain" "http://localhost:8080/api/send" -d "hello"
Test Class
@SpringBootTest
@EmbeddedKafka(partitions = 1, topics = "messages")
class KafkaTests {
@Autowired
private KafkaProducer producer;
@Test
void testMessageFlow() {
producer.sendMessage("test");
// Add assertions (e.g., mock consumer or log check)
}
}
Kafka Streams Example
Process data with Spring Kafka Streams:
@Configuration
@Component
public class MessageTopology {
@Autowired
public void buildTopology(StreamsBuilder builder) {
builder.stream("messages", Consumed.with(Serdes.String(), Serdes.String()))
.groupByKey()
.count()
.toStream()
.to("message-counts");
}
}
Counts messages in messages topic by key and outputs to message-counts topic.
Kafka vs. RabbitMQ
 Kafka isn’t the only message broker. How does it compare to RabbitMQ?
Kafka isn’t the only message broker. How does it compare to RabbitMQ?
| Feature | Kafka | RabbitMQ |
|---|---|---|
| Storage | Persists messages (like a library) | Deletes after delivery (like a mailbox) |
| Metaphor | Netflix: replayable streams | TV: live broadcasts |
| Queues | Simple partitions | Priority queues, complex routing |
| Model | Pull (consumers fetch) | Push (broker delivers) |
| Use Case | Streaming, log aggregation | Task queues, RPC |
Spring supports both, but Kafka excels at high-throughput, durable messaging.
Kafka’s Protocol
Kafka uses a custom TCP-based binary protocol:
- Efficient: Binary format reduces overhead.
- Port: Default 9092 (or 9093 for SSL).
- Pull Model: Consumers request data, unlike RabbitMQ’s push.
Spring Kafka abstracts this with KafkaTemplate and @KafkaListener, so you rarely touch the protocol directly.
Potential Misuses
 Nothing in tech world comes as a panacea:
Nothing in tech world comes as a panacea:
- Overcomplicating Simple Tasks: Kafka’s overhead isn’t worth it for basic request-response scenarios—use REST or RabbitMQ instead.
- Ignoring Retention: Storing messages forever without cleanup can balloon storage.
Resources to Learn More
Conclusion
Kafka, with Spring, transforms how services communicate—decoupling them for resilience, scaling them with partitions, and tracing them with tools like Micrometer. Whether you’re queuing messages, streaming data, or aggregating logs, Kafka’s flexibility shines. Try the examples above, experiment with KRaft, and see how Spring Kafka simplifies your next project. Happy coding!